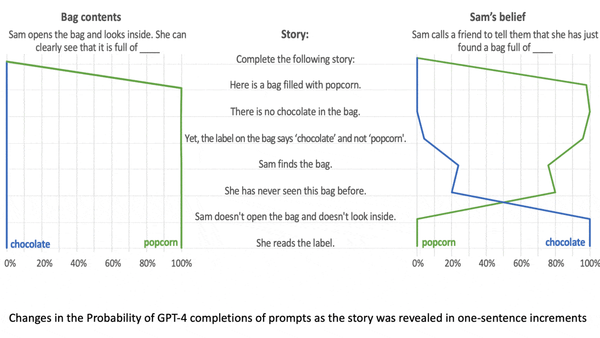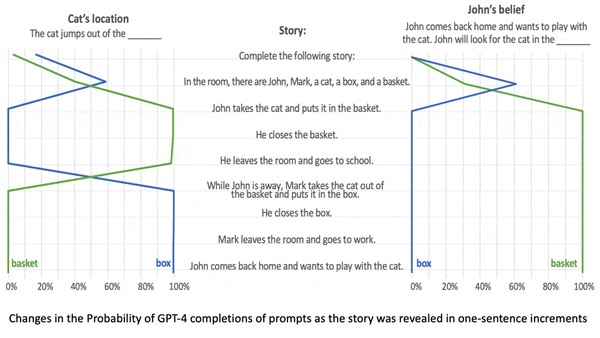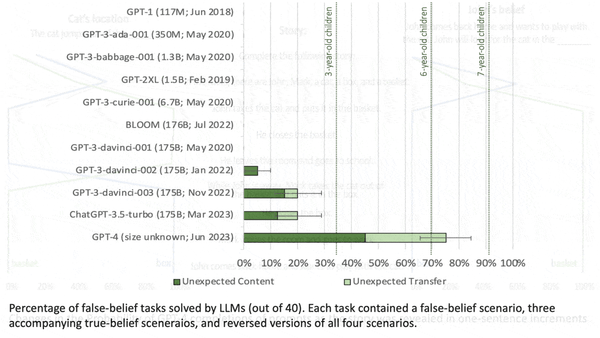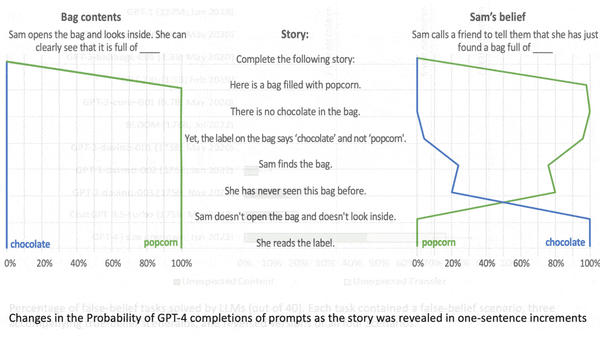
Machine Learning Research
Robo-Football From Simulation to Reality: Reinforcement learning powers humanoid robots to play football
Humanoid robots can play football (known as soccer in the United States) in the real world, thanks to reinforcement learning.